



 日本父女乱伦
日本父女乱伦
最早推出Transformer架构的谷歌,一度在大模子竞赛中落伍。好在跟着Gemini的抵制进化,谷歌正在回到第一梯队。
3月26日,Gemini2.5Pro上线,这个模子也曾推出就登顶各大榜单,在ChatbotArena上较第二名向上整整39分!
Gemini2.5Pro是一款推理模子。谷歌示意,推理身手不单是指分类和展望,而是指系统分析信息、得出逻辑论断、融入高下文和狭窄差异,以及作念出理智决策的身手。
据悉Gemini2.5Pro当今维持100万token的高下文窗口,很快将推出200万token的高下文窗口,经受并发达了Gemini模子的上风——原生多模态身手和超长高下文长度。
这让它梗概透露海量数据集,并处分来自多种信息源的复杂问题,包括文本、音频、图像、视频,甚而齐全的代码仓库。
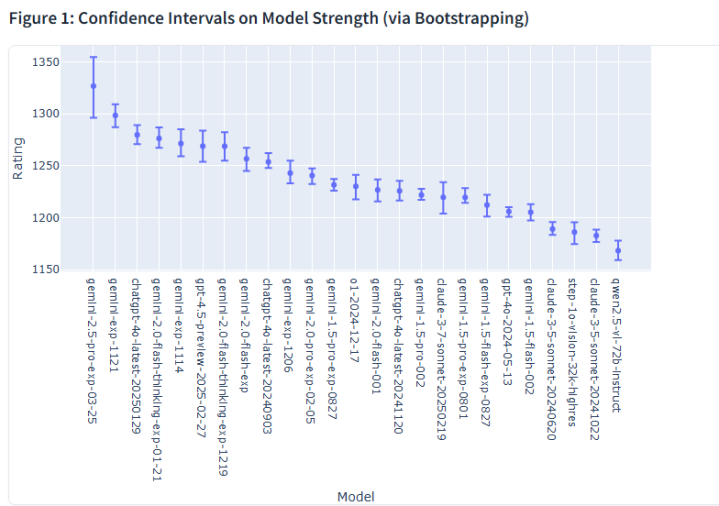
在ChatbotArena(由加州大学伯克利分校SkyLab和LMSYS的接洽者建造,主要用于字据东说念主类偏好评估大言语模子的性能)上,Gemini2.5Pro以横扫所有类别的权贵上风排名第一,而况比紧随后来的Grok-3整整向上了39分。
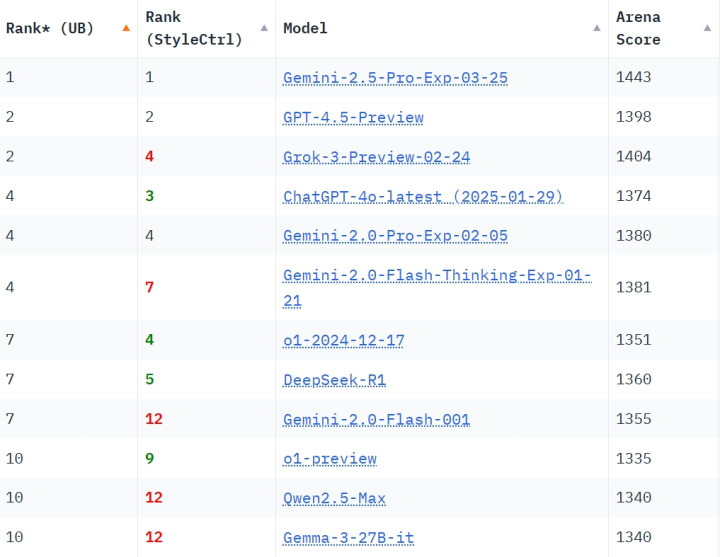
同期Gemini2.5Pro还取得了创意写稿、教唆遵照和长查询三大边界独一的冠军。
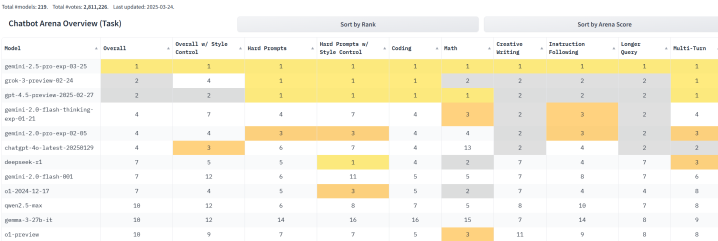
此外,Gemini2.5Pro收效登顶了视觉竞技场(VisionArena)排名榜榜首。
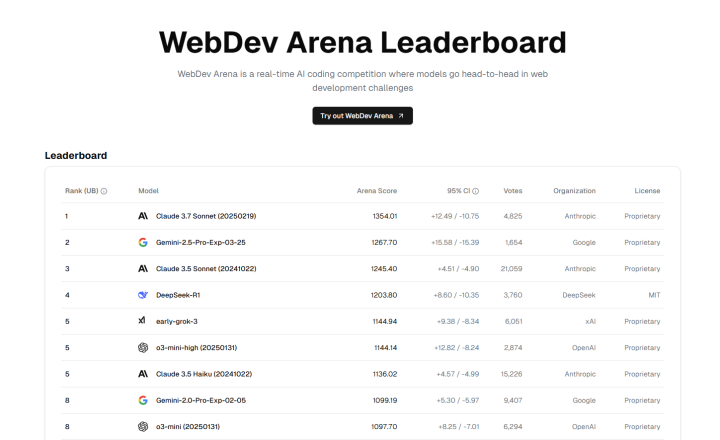
在网页建造边界,看成首个实力忘形Claude3.7Sonnet的模子,Gemini2.5Pro收效取得了网页建造竞技场(WebDevArena)的第二名。
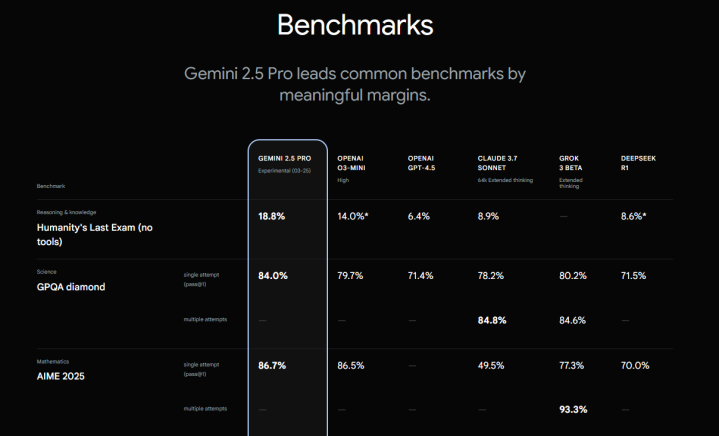
不仅如斯,Gemini2.5Pro在Humanity’sLastExam(notools),GPQA和AIME2025等数学和科学基准评测中相通施展不凡。
Humanity’sLastExam(notools)即“东说念主类的临了检修(无器具)”,这里的“无器具”指在进行该检修时,不允许使用外部器具,如搜索引擎、数据库等。昔日实践深入,开端进的LLMs在HLE上的准确率多量低于10%,且存在信心与身手失衡、推理着力低等问题,标明面前LLM的身手与东说念主类内行在阻滞式学术问题上的前沿身手之间的差距。在这一布景下,Gemini2.5Pro18.8%的得益显得特别隆起。
据悉,Gemini2.5Pro已在GoogleAIStudio和Gemini利用中,向GeminiAdvanced用户敞开,并将在VertexAI上推出。
而它会在畴昔几周内公布订价决策,用户不错在更高使用配额下,将模子利用于大范畴分娩环境。
有真理的是,最近国内和海外两大盛名的“起大早赶晚集”选手齐发布了最新大模子日本父女乱伦,含金量是否齐能达到评测深入的后果呢?